Schema vs Query-based Multitenancy
Most SaaS application are “multi-tenancy” to some extent (i.e., host more than one customer on the same system) but typically the term is reserved for apps that have company accounts, each with multiple users, authorisations etc. These companies would like to believe that company.mywebapp.com is their instance of MyWebApp and that you’ve lovingly prepared and set aside dedicated hardware for them. In practice, of course, you’d want all customers to share the same servers and database.
How you segregate customers within a database usually comes down to two approaches: query scoping or Postgres schemas. Query scoping works by ensuring that all queries are restricted to items within the same company using a WHERE clause. Postgres schemas are more complicated: they allow you to create identical copies of the database structure within the same database, and switch between them. It’s like creating a street of identical cookie-cutter houses, each containing the same rooms but with different people living inside. You can choose which house (schema) to visit but, once inside, you can’t see the inhabitants of the other houses.
Query Scoping
The structure is that you’ll have many Companies, each of which has many Users. It’s pretty simple to see that select * from users can be changed to select * from users where company_id=1 to just display the users of the current company instead of everyone in the application. And second order objects owned by a user, like a task list, can be scoped as usual: select * from task_lists where user_id = 1. The problem comes around authorisations, where multiple users can access the same things within their company. For example, a user might be able to access their task lists, but an admin might be able to access any task list in the company. Now you’ll either need a company_id column in the task_lists table or, more properly, do a join with the users table and select just those lists that belong to users in the same company as the admin.
SELECT task_lists.*
FROM task_lists
INNER JOIN users ON task_lists.user_id = users.id
WHERE users.company_id = 22
Urgh. And that’s before we do any actual filtering related to our application (like finding task lists with overdue tasks etc). The problem with relying on this scoping isn’t technical, it’s people. Will you, and every developer you hire in the future, remember to do this properly? Frankly, I’m a bear of little brain and I prefer not to have to think about this stuff for every single query.
Postgres Schemas
With the Postgres schema approach, we first have to choose the ‘house’ we’re going to visit. In a web application, this is typically done early on in the request cycle by calling SET search_path TO mycompany,public. This says, “first use the mycompany schema, but fallback to the public (default) schema”. Now, I can call select * from users and I’ll only ever get the contents of the users table in the mycompany schema, and not the contents of the users table in any other schema. Likewise, an admin looking for all task lists is simplified to select * from task_lists. No company scoping with WHERE clauses. No table joins.
It’s a highly effective way at maintaining data segregation and simplifying your application code.
Why would you choose schemas?
Firstly, I think schema-based segregation provides a great peace of mind to the developer. It’s one less thing to think about when writing new queries or fixing a defect under-pressure. I guess I just don’t trust myself not to make a mistake every once-in-a-while and I appreciate the secure-by-default design of the schemas. For example, even if you left yourself open to an SQL injection attack and the database tried to query SELECT * FROM projects WHERE name = '' OR 1 --' (i.e., returning all projects) it would still only return all the projects within one company, not the whole database. Naturally, if you have SQL injection vulnerabilities, you have major problems but I’ll take whatever levels of security I can get!
Another good reason to choose a schema-architecture is if you think you will ever need to offer dedicated hardware. These days it seems inconceivable that anyone would offer dedicated servers for a SaaS product but governments, public bodies and large corporation could well require (and pay justifiably for) their own dedicated resources. Moving a single domain, query-scoped database to this model would be daunting but schemas already act like separate databases. Moving to dedicated hardware would (roughly!) be a matter of dumping the schema to a new db server and updating the DNS entries for that subdomain.
For certain types of customers, using schemas can provide a good security story. Do your customers ask about security? Ours do. We’re frequently asked whether their data is stored alongside other customers’. They really don’t like it when you say everything is in the same db, and whilst still true with schemas, it gives you a much better story to tell. I’d say if you ever expect a customer to write you a $10,000 cheque, then you’re probably in the territory where schema-segregated databases are required.
Subdomains
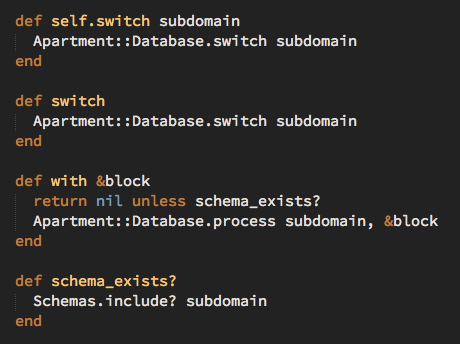
Multi-tenant apps using schemas are often associated with the use of subdomains, since this is usually how the current schema gets set. In Rails, you’d use something like Apartment which provides a Rack middleware that uses the subdomain as the schema search path (i.e., mycompany.app.com uses the mycompany schema). Whilst their use is associated with schemas, subdomains can also be used with standard query scoping.
Subdomains, irrespective of the underlying database structure, also offer a number of useful features: they look better and provide trust to enterprise customers; they provide additional security due to cookie domain restrictions
Issues with Schemas
Life with a schema-based multi tenant app isn’t all rosey though.
Most notably, it makes testing a little bit more complicated. For the most part you can create your fixture objects in the public schema for model-level testing and it’ll work fine. For testing controllers or running integration tests, you’ll need to either disable the schema switching, or you’ll need to create the test data in the appropriate schema. In my experience, there can also be conflicts with transaction-based rollbacks of test data involve schema creation.
Another problem with segregating data by schemas is just that: the data is segregated. So if you plan on, for example, querying for all users of your application you can simply run select * from users. Now you need to iterate over each company, run the query inside each schema, and then aggregate the results. This can make whole-app analytics a little more complicated. It’s definitely a trade-off between security and ease-of-use.
Likewise, out-of-request processes like background jobs become more complicated. Whereas our HTTP requests safely switch schemas based on the subdomain, we need a mechanism for doing the same in our background jobs. Apartment comes with support for Sidekiq (and previously for DelayedJob) but it’s worth bearing in mind the slight addition in complexity. Also, rake tasks will also need to switch to the appropriate schema when operating on a particular company. Likewise, when running rails console, you’ll need to switch to a company’s schema before interacting with the data. And, you’ll need to be careful if you store user uploads using, for example, the user id as a key. Your user id’s are no longer globally unique, they’re only unique within the company’s schema so you’ll need to include that in your directory structure.
One other thing that’s made more complicated: supporting Postgres extensions like HSTORE. Extensions are installed into a particular schema, and can’t be installed in multiple schemas. The solution is to create an additional schema solely for extensions and then reference it in the schema_path. I talk through the details in this post about creating user settings and Apartment also has a good write-up
Any form of centralised login functionality (i.e., where people can login on your home page, instead of their subdomain) becomes that bit harder too. There are some solutions that I can think of like storing email -> subdomain mappings in a public table, then switch to the appropriate subdomain during the login process. But, yeah, it’s definitely more complicated.
Do you want one person to have an account at many companies? Most people instinctively say no, but consider this: consultants will often want to be in, or manage, accounts for each client. In order to have accounts in multiple companies, a user will need multiple login details at each subdomain. And, whilst they can be logged into each one at the same time, they won’t be able to switch between them in the app or share any data between their accounts (like user name, avatars etc).